[Readings]
[Exercises]
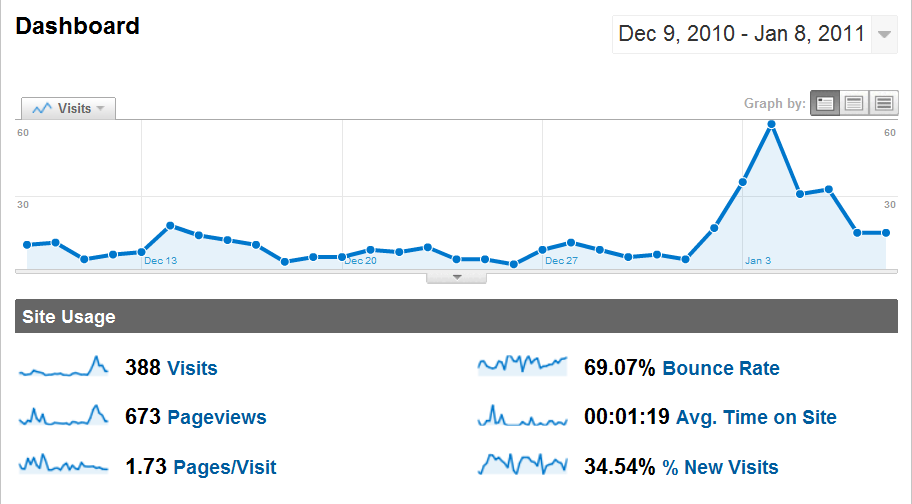
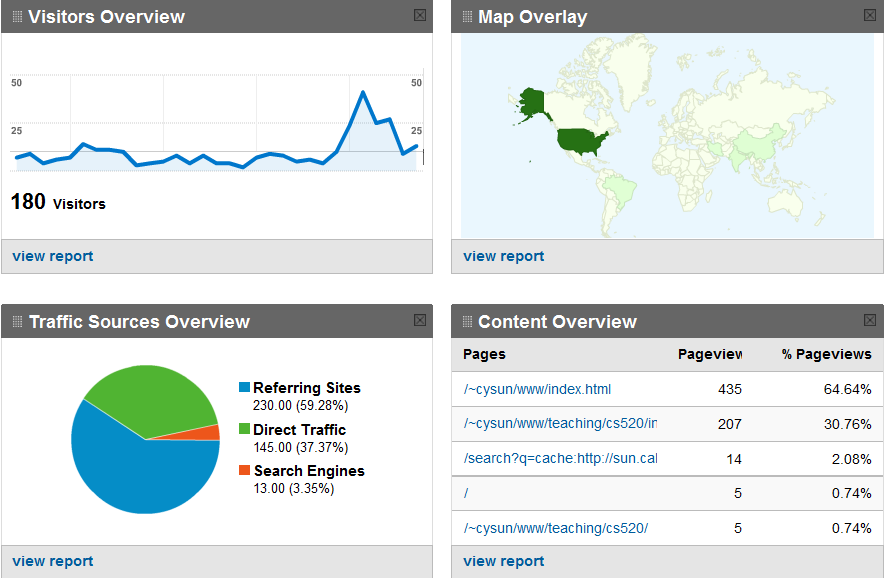
1. (25pt) The following two screenshots show some samples of the reports provided by Google Analytics:
Suppose you want to develop a web analytics service that competes with Google Analytics, and the raw data for the service is stored in a table with the schema (request_id, session_id, client_address, url, referrer, timestamp).
(a) Design a Star/Constellation Schema for your service to efficiently support the reports shown in the screenshots. Describe the preprocessing that is needed to transform the raw data into the data under the new schema.
(b) Complete the following SQL queries using the new schema:
Use these queries as examples to explain why it is more efficient to produce the reports using the preprocessed data under the new schema instead of using the raw data.
2. (15pt) Consider a data cube with n dimensions and the cardinality of each dimension is m.
(a) How many cuboids are there in this data cube?
(b) How many cells are there in a k-dimensional cuboid?
(c) How many cells are there in the whole data cube?
(d) Suppose n=10 and m=20, and each cell requires 4 bytes to store. How many 1TB hard disks are needed to store all the cells in the data cube?
3. (15pt) Consider a 10-dimensional data cube with the measure COUNT. The base cuboid of this cube contains only three non-zero cells:
List all the closed cells in this data cube.
4. (15pt) Consider a 4-dimensional data cube with dimensions A, B, C, D, and the cardinality of each dimension is 10000, 1000, 100, 10, respectively. Suppose we want to use Multiway Array Aggregation to compute the 3-D cuboids from the base cuboid. The base cuboid is divided into chunks by partitioning each dimension into 10 equal portions. What is the order to read the chunks into memory that minimizes the memory requirement? In particular, how many 3-D cells need to be kept in memory when the chunks are read in this order?
5. (15pt) Consider the following dataset with three dimensions A={a1,a2}, B={b1,b2,b3}, C={c1,c2,c3,c4} and the measure SUM:
List all the cells in the iceberg cube with SUM > 5 in the order produced by the BUC algorithm.
6. (15pt) Consider the the following dataset with five dimensions A, B, C, D, E and the measure SUM:
(a) Construct shell fragments (A,B) and (C,D,E).
(b) Use the shell fragments you constructed in (a) to answer the query (*,b1,*,d1,*,?).
{kind=link}
{kind=link}